Presentation
Introduction
CBIRest is a Content-based image retrieval (CBIR) web application. Its a REST API for the Java CBIRetrieval lib.Content-based image retrieval (CBIR), also known as query by image content (QBIC) and content-based visual information retrieval (CBVIR) is the application of computer vision techniques to the image retrieval problem, that is, the problem ofsearching for digital images in large databases. Content-based image retrieval is opposed to traditional concept-based approaches (see Concept based image indexing). "Content-based" means that the search analyzes the contents of the image rather than the metadata such as keywords, tags, or descriptions associated with the image. The term "content" in this context might refer to colors, shapes, textures, or any other information that can be derived from the image itself.

CBIRest API is:
- A REST API for CBIR: You will be able to perform HTTP request to search for similar images and to add/remove images in the CBIR index.
- web: packaged with a full web client.
- incremental: add new images all over the time.
- scalable: run as many server as you want. Client may search on all servers (not yet production ready).
- easy to customise: build using Java/Spring (server) and AngularJS (client).
- free: Free and Opensource (Apache 2.0).
If you are looking for a Content-based image retrieval Java library, you should see CBIRetrieval Java lib. It provides the same functionalities as the CBIRest API, but you can use it as a simple app/server (command line) or as a JAR in your own JVM app/server (java import).
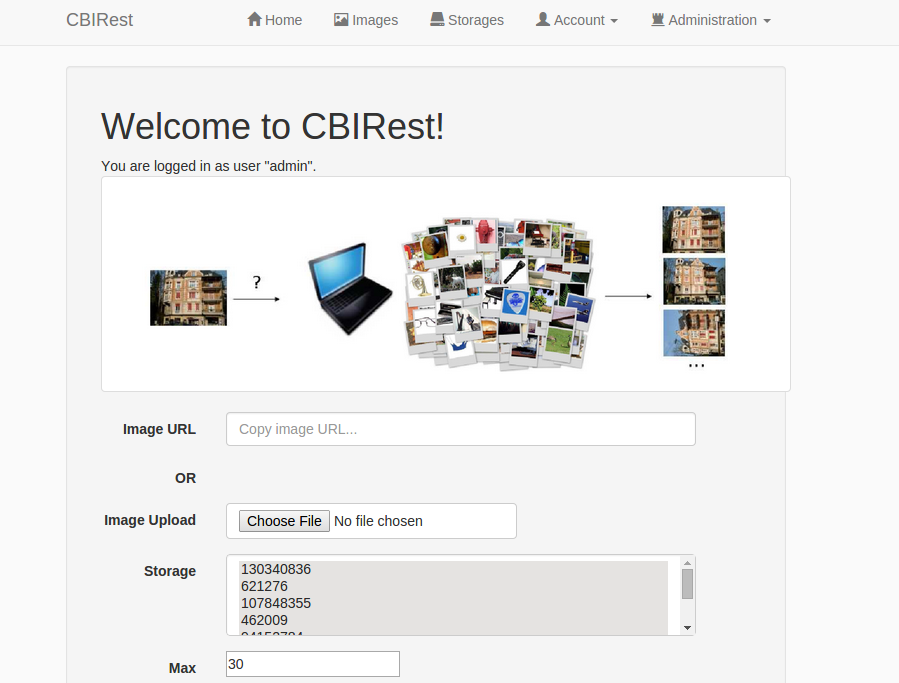
UI interface
CBIRest is not only an REST API, its a webapp too. The application is packaged with a web client. This is usefull for management task (add, delete images,...) and to perform some tests.
The web application provides some functionalities:
- Search for similar images
- Add/Delete images from index
- Manage storages (virtual space)
- Change user password
- Server Metrics/Health
- ...
Installation
Requirements
- Linux, Mac OS (Windows should work)
- Java 8
- Redis (not mandatory)
- Tomcat 7 (not mandatory)
Redis is mandatory if you want persistance. If you use Memory mode, you will lost your data if you reboot the app.
Download
Download the last distribution hereThe retrieval-*.war file from the zip is a war with an embedded TOMCAT server (for quick install). The other war (.war.original) can be install inside a web server/servlet container (only test with tomcat).
Quick install
- Download the last distribution
-
Replace $VERSION with the last version and run:
unzip CBIRest-$VERSION.zip cd CBIRest-$VERSION java -jar retrieval-$VERSION-SNAPSHOT.war --spring.profiles.active=prod --retrieval.store.name=MEMORY - open your browser and go to http://localhost:9999/
Advanced install
The advanced installation use redis instead of a simple memory database.- Download Redis
- Install Redis if not yet done. By default, Redis needs to be run on localhost:6379 (default value).
- Launch Redis if not yet done:
./redis-server - See the Quick install task (replace --retrieval.store.name=MEMORY with --retrieval.store.name=REDIS
When you are ready, change your user/admin password (user/user, admin/admin by default)!!!
Perform a quick test
When you first run the software, you can easily index a dataset. The WANG dataset:- Download the images archive (+-40MO) from http://wang.ist.psu.edu/docs/related/.
- Extract the dataset
-
Run this command when you want to start CBIRest (replace $PATH with the dataset path, $VERSION with the good version):
java -jar retrieval-$VERSION-SNAPSHOT.war --spring.profiles.active=prod --retrieval.store.name=MEMORY --retrieval.dataset.load=true --retrieval.dataset.path=$PATH
Build from sources
- Source can be found on github: github.com/loic911/CBIRestAPI
-
mvn -Pprod package -Dmaven.test.skip=true - War(s) should be available in target/
- Create a new directory based on release/template and copy the war(s) file(s). You should be able to run the installation steps.
Configuration
Configuration can be done on multiple level.
- CBIRest API: configuration for the main CBIR system.
- CBIRetrieval: more precise configuration for the CBIR engine.
- Redis: configuration for the database.
CBIRest API Configutation
Main configuration flags for CBIRest application. Just append these config params after the "java -jar..." command when you launch the app. E.g. --retrieval.store.name=MEMORY.
| Name | Values | By default |
|---|---|---|
| --retrieval.store.name | MEMORY (by default in dev), REDIS (by default in prod) | Change the database engine. Memory is not persistant! |
| --retrieval.dataset.load | true, false (by default) | Flag if the app must index a dataset at the startup (see "Perform a quick test" section) |
| --retrieval.dataset.path | A path | Dataset path, only usefull if --retrieval.dataset.load is true |
CBIRetrieval Configuration
CBIRest API is a HTTP API for the CBIRetrieval Java lib. Most of the configuration are defined by the configuration files from CBIRetrieval Java lib: config/ConfigServer.prop and config/ConfigClient.prop. Check the config/*.prop files inside your installation package to have the last version. The full documentation is available on the CBIRetrieval Java lib wiki.
You can change these parameters by editing the ConfigServer and configClient.prop files. Some of these configuration can be overrided by the CBIRest API configuration flags. For the default value, check your Config*.prop files.
We just list here the most important flags:
| Name | Values | By default |
|---|---|---|
| Database config | ||
| STORENAME | MEMORY, REDIS | Change the database engine. Memory is not persistent! |
| REDISHOST | IP, server name,... | If you use Redis, Redis host. |
| REDISPORT | Port | If you use Redis, Redis port |
| Quality VS speed config | ||
| NUMBEROFPATCH | Number | Number of patch (N) for index request picture. HIGH = better quality, bad perf |
| NUMBEROFTV | Number (max 50) | Number of test vector (T), HIGH = better quality, bad perf |
| Location | ||
| VECTORPATH | Path | Path to the tests vectors (testsvectors/) |
HTTP Request
How it works
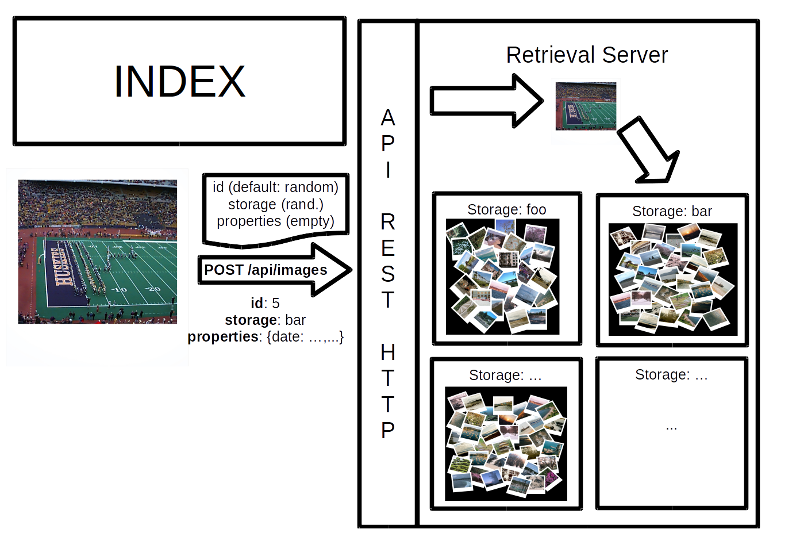
Index
You first need to index images on the server. CBIRest is incremental, this means that you can add new images to the index all over the time. Index image can be done with a POST /api/images. You need to provide the image binary data as a multipart content. You may specifiy the image id (by default: a random number), the storage (by default: a random storage) and some properties (by default: an empty map).
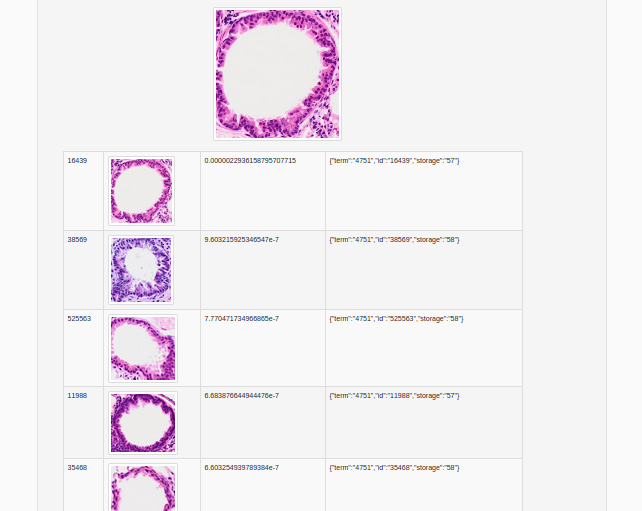
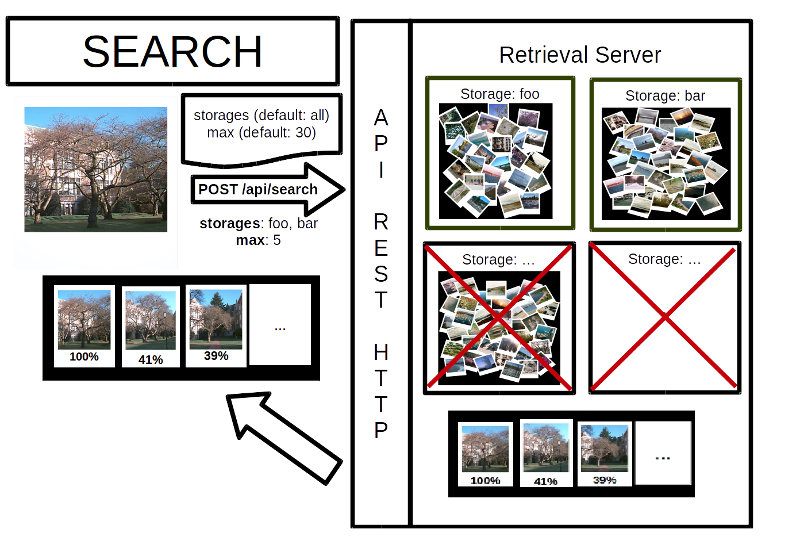
Search
Simply provides an image and the storages (by default the search will be done on all available storages). The service can be reach thanks to a POST in /api/search. The CBIRest server provides a list of similar pictures (sort by similarities). For each image, the server return the id, storage and properties.
Images API
Presentation
Each image that appears in the CBIR results needs to be indexed to the server first. The server extracts data and index these information in a specific storage database (MEMORY or REDIS). An image is identified with an id (long number) and you may add extra information (like date, path,...). Each time a new image is added, the server saves its thumb on the filesystem too.
Actions
| Description | Verb/Path | Params | Response |
|---|---|---|---|
| Get all images | GET /api/images |
List of images data:
|
|
| Get all images for a storage | GET /api/{storage}/images |
|
List of images data:
|
| Get a single image data | GET /api/images/{id}, GET /api/storages/{storage}/images/{id} (better for performance) |
|
Image data:
|
| Add a new image | POST /api/images |
|
Image data:
|
| Delete an image image | DELETE /api/storages/{storage}/images/{id} |
|
Deleted Image data:
|
| Retrieve image thumb | GET /api/images/{id}/thumb |
|
Image thumb |
| Index a full set of data. Quick way to index a lot of images. | POST /api/index/full | JSON with [{"id":...,"storage":...,"url":...},...] |
Storages API
Presentation
A storage is a virtual space on the server. You can store all images inside a single storage but its not a perfect solution. The storage concept allows you to:
- You can filter search by storage: If you have storages “a”, “b” and “c” , you can perform search requests only on storages “a” and “c”. Less data for the search computation so better performance. This is usefull if your images dataset may be split thanks specific criteria.
- You can split your dataset: When you perform a search request, there will be as many threads as storages. When you add an image, there will be one thread for each storage. This means that if you perform a lot of search on all storages, its better to have N storages where N is the number of Core available in the server.
Actions
| Description | Verb/Path | Params | Response |
|---|---|---|---|
| Get all storages | GET /api/storages |
List of storages data:
|
|
| Get a specific storage | GET /api/storages/{id} |
|
Storage data:
|
| Create a new storage | POST /api/storages | JSON string in body: {"id":"$NAME"} |
Storage data:
|
| Delete a storage. All images data in this storage will be deleted. | DELETE /api/storages/{id} |
|
Search API
Presentation
The search API provides methods to search images similarities.
Actions
| Description | Verb/Path | Params | Response |
|---|---|---|---|
| Search for similar images | POST /api/search |
|
Request id and results under "data":
|
| Search for similar images | POST /api/searchUrl |
|
Request id and results under "data" (for each image: id, storage, properties and similarities):
|
Databases
Image data needs to be store in very large hash table. You can choose between MEMORY or REDIS implementation.
- MEMORY: easy to use (no external app needed) and very fast but it use a lot of memory and its not persistent. If your app crash, you need to index again all images after rebooting.
- REDIS: powerful free key-value database with persistence support.
Performance/Speed
Some tips to improve performance:- Reduce NUMBEROFPATCH: Each time you index an image, there will be NUMBEROFPATCH * NUMBEROFTV data that will be store. If you reduce this number, the results quality will be poor but the speed will be better. If you reduce this number in config/ConfigServer.prop file, index and search will be faster. IF YOU CHANGE THIS NUMBER, YOU MUST DROP YOUR EXISTING INDEX AND REINDEX ALL YOUR IMAGES!!! if you reduce this number in config/ConfigClient.prop file, search will be faster (but no need to reindex).
- Reduce NUMBEROFTV: If you reduce this number, the results quality will be poor but the speed will be better too.
- MEMORY VS REDIS: Memory has better performance than Redis.
- Use Storage: See storage section.
Scalability
The CBIRetrieval Java lib used in CBIRest server support distributed deployment. In the future, you should be able to run multiple CBIRest server and perform search simultaneously on all of them. By now, there are only working prototype but its not ready for production.
Concrete use case
Integration with Cytomine
Cytomine Presentation
Cytomine is a rich internet application for visualization, collaborative annotation, and automatic analysis of large-scale bioimages.
The goal of the CYTOMINE project is to develop a modern internet application using data mining for large-scale bioimage exploitation in order to help life scientists to better evaluate drug treatments, understand biological processes, and ease diagnostic. Our application uses fully web-based technologies without the need for the end-user to install proprietary softwares to visualize, annotate, and analyze imaging data. Although our initial focus was on lung cancer and inflammation in cytology and histology images, we seek to provide a generic software and tailored services for other diseases, biological processes, and also other types of high-dimensional imaging data.
One of the key concept of Cytomine is the ability to draw annotations on an image. You can annotate your images by drawing multiple regions of interest (ellipses, rectangles, polygons, freehand drawings) and associate them to user-defined terms from structured vocabularies (ontologies).
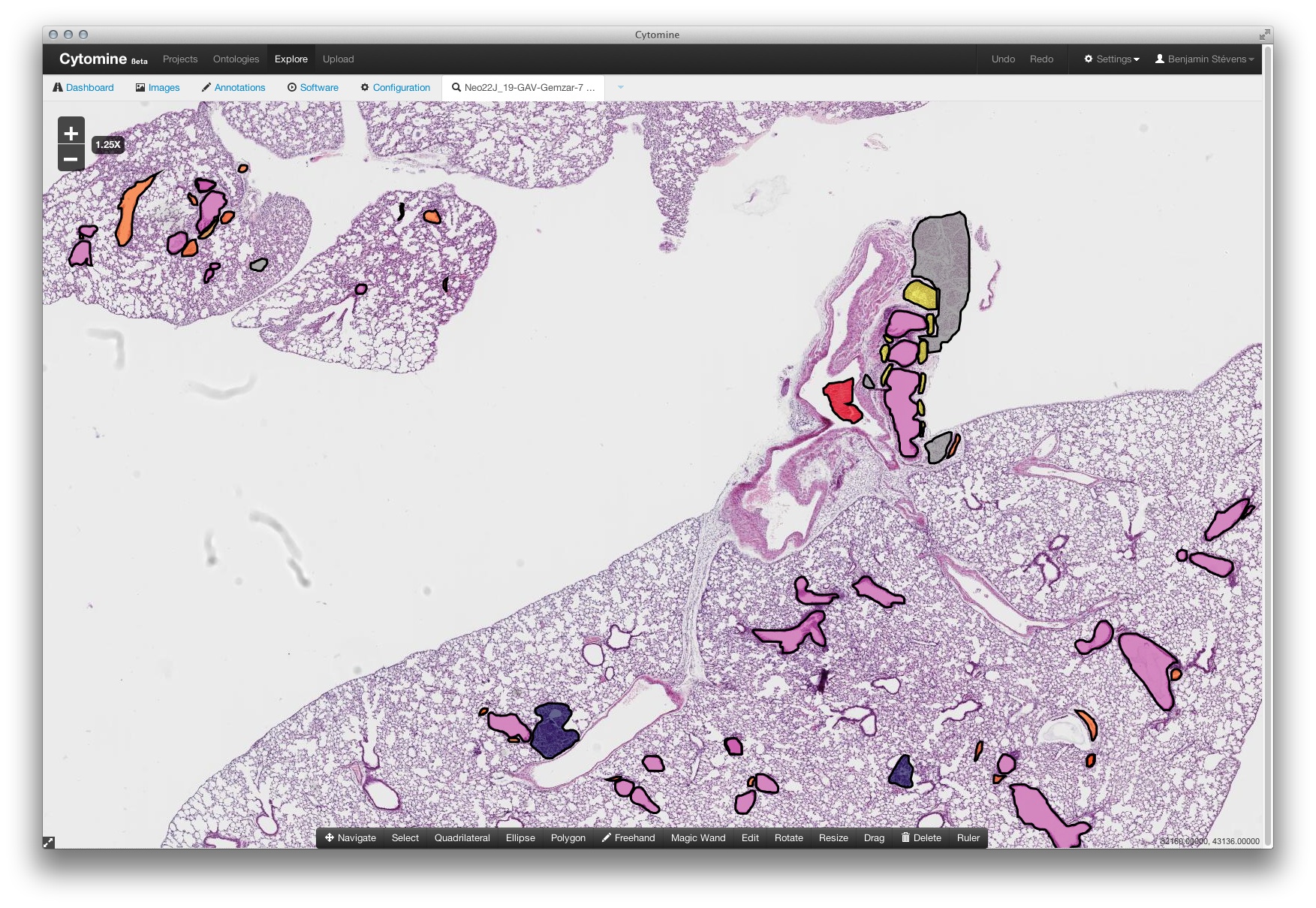
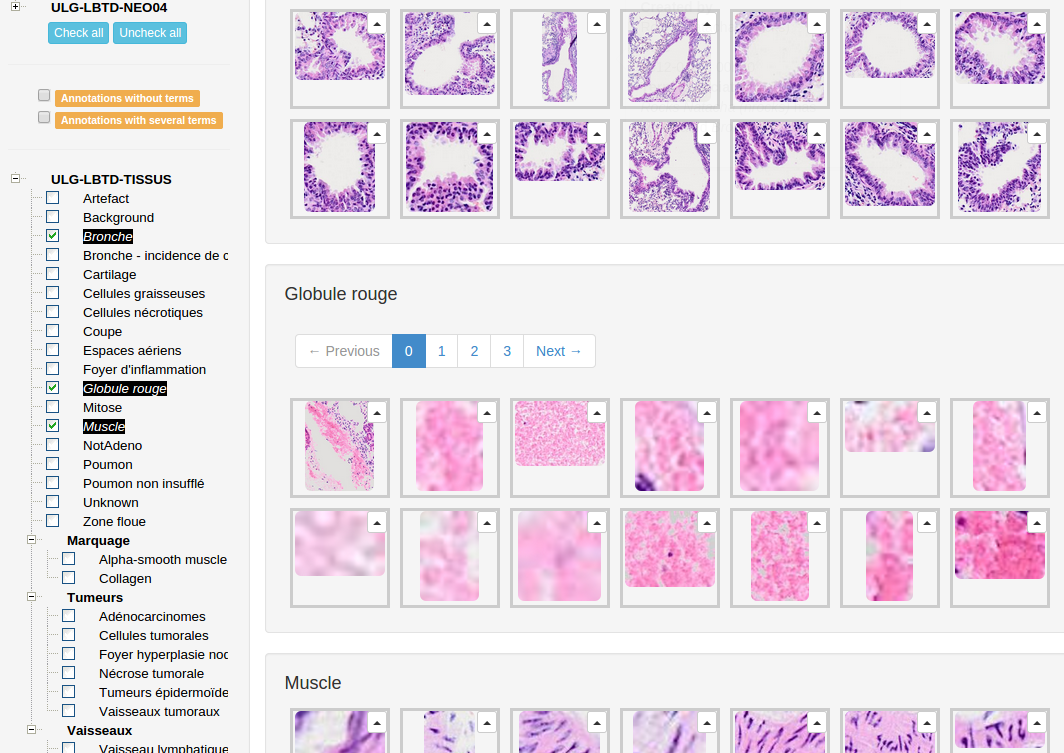
Retrieval integration with Cytomine
Each time a user draw an annotation, we retrieve the annotation images and we send an index HTTP request to the CBIRest API server.
Each time a user click on an annotation, we retrieve the annotation images and we perform a search request on the CBIRest API server. This server responses a sorted list of similar annotations id.

Thanks to the annotations lists and their respective similarities, Cytomine compute the “suggested terms”. If the CBIR results contains a lot of annotation from term X with a high similarities rate, the system suggests this annotation (e.g. Tumor: 91%, artefact: 5%,...).
In Cytomine, images (and their annotations) are stored inside Projects. A project has its own ontology (terms list) but an ontology can be associated with multiple projects. This means that its not necessary to search on annotations similarities from project with different ontology. In Cytomine, we create one storage per project and we index an annotation in its project storage. Thanks to that we can search similar annotations only on the current project or on all projects sharing the same ontology. Less computation, better performance!
Help/Questions
Issues/questions can be post on the github issue page
There are a lot of improvement that can be done:
- Better integration with redis
- Improve web UI
- Add new database support
Contributors/License
List of contributors:
This software is an optimized, multi-threaded, implementation of the algorithm described in this original research article:
Incremental Indexing and Distributed Image Search using Shared Randomized Vocabularies
/*
* Copyright 2015. Authors: ROLLUS Loïc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/


